 This version (2021/10/11 05:18) is a draft.
This version (2021/10/11 05:18) is a draft.Approvals: 0/1
This is an old revision of the document!
Computational Fluid Dynamics
ANSYS-Fluent (CFD)
Module
Check available versions of Ansys:
module avail 2>&1 | grep -i Ansys
Load the correct version of Ansys, e.g.,
module load *your preferred module*
available modules on VSC-4:
- ANSYS/2019R3
- ANSYS/2020R2
- ANSYS/2021R1
General Workflow
The subsequent figure shows an overview of the general workflow if you use Fluent on your local machine for Pre- and Postprocessing and the cluster for solving your case, respectively.
For this workflow a graphical connection isn't necessary.
All files needed for this testcase are provided here: fluent_testcase.zip
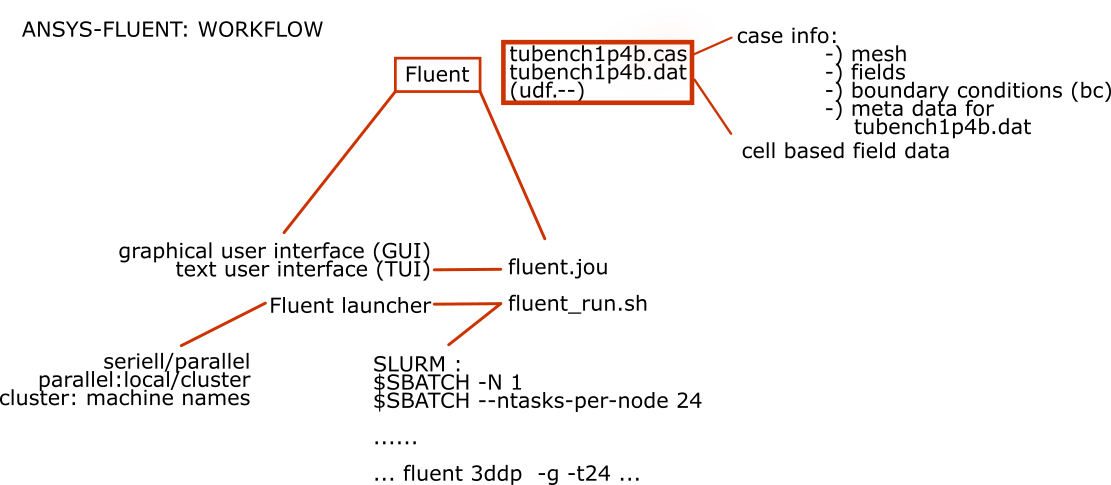
Input file
Create a journal file (fluent.jou) which is written in a dialect of Lisp called Scheme and contains all the instructions that are to be executed during the run. A basic form of this file, is as follows:
# ----------------------------------------------------------- # SAMPLE JOURNAL FILE # # read case file (*.cas.gz) that had previously been prepared file/read-case "tubench1p4b.cas.gz" file/autosave/data-frequency 10 solve/init/initialize-flow solve/iterate 500 file/write-data "tubench1p4b.dat.gz" exit yes
The autosave/data-frequency setting will save a *.dat file every 10 iterations.
But preferably do this settings in the GUI as shown in subsequent graphic.

Keep in mind to set the appropriate path for the cluster. Here the files will be saved in the same directory as the journal file is located. It could be better for the sake of clarity to create a additional directory for this backupfiles, i.e.
./Autosave/*your_filename*.gz
Job script
A script for running Ansys/Fluent called fluent_run.sh is shown below.
#!/bin/sh
#SBATCH -J fluent
#SBATCH -N 2
#SBATCH -o job.%j.out
#SBATCH --ntasks-per-node=24
#SBATCH --threads-per-core=1
#SBATCH --time=04:00:00
module purge
module load *your preferred module*
JOURNALFILE=fluent.jou
if [ $SLURM_NNODES -eq 1 ]; then
# Single node with shared memory
fluent 3ddp -g -t $SLURM_NTASKS -i $JOURNALFILE > fluent.log
else
# Multi-node
fluent 3ddp \ # call fluent with 3D double precision solver
-g \ # run without GUI
-slurm -t $SLURM_NTASKS \ # run via SLURM with NTASKS
-pinfiniband \ # use Infiniband interconnect
-mpi=openmpi \ # use IntelMPI
-i $JOURNALFILE > fluent.log # input file
fi
This job script allows a variable definition of desired configuration. You can manipulate the number of compute nodes very easily and the job script generates the appropriate command to start the calculation with Fluent.
License server settings
These variables are defined when loading the fluent module file:
setenv ANSYSLI_SERVERS 2325@LICENSE.SERVER setenv ANSYSLMD_LICENSE_FILE 1055@LICENSE.SERVER
Submit job
sbatch fluent_run.sh
Restarting a calculation
To restart a fluent job, you can read in the latest data file:
# read case file (*.cas.gz) that had previously been prepared file/read-case "MyCaseFile.cas.gz" file/read-data "MyCase_-1-00050.dat.gz" # read latest data file and continue calculation solve/init/initialize-flow solve/iterate 500 file/write-data "MyCase.dat.gz" exit yes
ABAQUS
ABAQUS 2016
Sample job script
/opt/ohpc/pub/examples/slurm/mul/abaqus
#!/bin/bash
#
#SBATCH -J abaqus
#SBATCH -N 2
#SBATCH -o job.%j.out
#SBATCH -p E5-2690v4
#SBATCH -q E5-2690v4-batch
#SBATCH --ntasks-per-node=8
#SBATCH --mem=16G
module purge
module load Abaqus/2016
export LM_LICENSE_FILE=<license_port>@license_server>:$LM_LICENSE_FILE
# specify some variables:
JOBNAME=My_job_name
INPUT=My_Abaqus_input.inp
SCRATCHDIR="/scratch"
# MODE can be 'mpi' or 'threads':
#MODE="threads"
MODE="mpi"
scontrol show hostname $SLURM_NODELIST | paste -d -s > hostlist
cpu=`expr $SLURM_NTASKS / $SLURM_JOB_NUM_NODES`
echo $cpu
mp_host_list="("
for i in $(cat hostlist)
do
mp_host_list="${mp_host_list}('$i',$cpu),"
done
mp_host_list=`echo ${mp_host_list} | sed -e "s/,$/,)/"`
echo "mp_host_list=${mp_host_list}" >> abaqus_v6.env
abaqus interactive job=$JOBNAME cpus=$SLURM_NTASKS mp_mode=$MODE scratch=$SCRATCHDIR input=$INPUT
ABAQUS 2016
Checkpointing and restart
Users sometimes find that their jobs take longer than the maximaum runtime permitted by the scheduler to complete. Providing that your model does not automatically re-mesh (for example, after a fracture), you may be able to make use of Abaqus’ built-in checkpointing function.
This will create a restart file (.res file extension) from which a job that is killed can be restarted.
- Activate the restart feature by adding the line:
*restart, write
at the top of your input file and run your job as normal. It should produce a restart file with a .res file extension.
<HTML><ol start=“2” style=“list-style-type: decimal;”></HTML> <HTML><li></HTML>Run the restart analysis with<HTML></li></HTML><HTML></ol></HTML>
abaqus job=jobName oldjob=oldjobName ...
where oldJobName is the initial input file and newJobName is a file which contains only the line:
*restart, read
ABAQUS 2016
Checkpointing and restart
COMSOL
The following case is provided here including the directories-structure
and the appropriate batch-file: karman.rar
Module
Available version of Comsol can be found by executing the following line:
module avail 2>&1 | grep -i comsol
Currently these versions can be loaded:
- Comsol/5.5
- Comsol/5.6
module load *your preferred module*
Workflow
In general you define your complete case on your local machine and save it as *.mph file.
This file contains all necessary information to run a successfull calculation on the cluster.
Job script
An example of a Job script is shown below.
#!/bin/bash
# slurmsubmit.sh
#SBATCH --nodes=1
#SBATCH --ntasks-per-node=24
#SBATCH --job-name="karman"
#SBATCH --partition=mem_0384
#SBATCH --qos=mem_0384
module purge
module load Comsol/5.6
MODELTOCOMPUTE="karman"
path=$(pwd)
INPUTFILE="${path}/${MODELTOCOMPUTE}.mph"
OUTPUTFILE="${path}/${MODELTOCOMPUTE}_result.mph"
BATCHLOG="${path}/${MODELTOCOMPUTE}.log"
echo "reading the inputfile"
echo $INPUTFILE
echo "writing the resultfile to"
echo $OUTPUTFILE
echo "COMSOL logs written to"
echo $BATCHLOG
echo "and the usual slurm...out"
# COMSOL's internal command for number of nodes -nn and so on (-np, -nnhost, ...) are deduced from SLURM
comsol batch -mpibootstrap slurm -inputfile ${INPUTFILE} -outputfile ${OUTPUTFILE} -batchlog ${BATCHLOG} -alivetime 15 -recover -mpidebug 10
Possible IO-Error
COMSOL is generating a huge amount of temporary files during the calculation. These files in general got saved in $HOME and then this error will be occuring. To avoid it, you have to change the path of $TMPDIR to e.g. /local. So the temporary files will be stored on the SSD-storage local to the compute node.
To get rid of this error just expand the comsol command in the job script by the following option:
-tmpdir "/local"
Submit job
sbatch fluent_run.sh

| Parameter / Function Sweep | Batch Sweep | ||
|---|---|---|---|
| Loop | inner or outer | outer | outer |
| Settings in GUI | Enable distibute parameter sweep | Set number of simultaneous jobs |
|
| Entries on command line | –mpibootstrap slurm | –mode desktop | |
| Description | MPI -synch. | next job drops in free slots | |