 This version is outdated by a newer approved version.This version (2018/01/16 13:05) is a draft.
This version is outdated by a newer approved version.This version (2018/01/16 13:05) is a draft.Approvals: 0/1
This is an old revision of the document!
GPU computing and visualization
The following GPU devices are available:
| Enterprise-grade Tesla k20m (kepler) | |
|---|---|
| Total amount of global memory | 4742 MBytes |
| (13) Multiprocessors, (192) CUDA Cores/MP | 2496 CUDA Cores |
| GPU Clock rate | 706 MHz |
| Maximum number of threads per block | 1024 |
| Device has ECC support | Enabled |
| Enterprise-grade Tesla m60 (maxwell) | |
|---|---|
| Total amount of global memory | 8114 MBytes |
| (16) Multiprocessors, (128) CUDA Cores/MP | 2048 CUDA Cores |
| GPU Clock rate | 1.18 GHz |
| Maximum number of threads per block | 1024 |
| Device has ECC support | Disabled |
| Consumer-grade GeForce GTX 1080 (pascal) | |
|---|---|
| Total amount of global memory | 8113 MBytes |
| (20) Multiprocessors, (128) CUDA Cores/MP | 2560 CUDA Cores |
| GPU Clock rate | 1.73 GHz |
| Maximum number of threads per block | 1024 |
| Device has ECC support | Disabled |
- Two nodes, n25-[005,006], with two Tesla k20m (kepler) GPUs each. Host systems are equipped with two Intel Xeon E5-2680 0 @ 2.70GHz each with 8 cores and 256GB of RAM.
- One node, n25-007, with two Tesla m60 (maxwell) GPUs. n25-007 is equipped with 2 Intel Xeon E5-2650 v3 @ 2.30GHz, each with 10 cores and a host memory of 256GB RAM.
- Ten nodes, n25-[011-020], with single GPUs of type GTX-1080 (pascal), where host systems are single socket 4-core Intel Xeon E5-1620 @ 3.5 GHz with 64GB RAM.
- Two shared-private nodes, n25-[021-022], each equipped with 8 GTX-1080 (pascal) devices hosted on dual socket 4-core Intel Xeon E5-2623 systems @ 2.6 GHz with 128GB RAM.
gdrdrv is loaded by default (also see notes regarding gtx1080 cards).
Slurm integration
There is one partition called gpu which includes all available gpu nodes
[user@l31 ~]$ sinfo -p gpu PARTITION AVAIL TIMELIMIT NODES STATE NODELIST gpu up infinite 10 alloc n25-[011-020] gpu up infinite 5 idle n25-[005-007,009-010]
and which needs to be specified via:
#SBATCH --partition=gpu
GPU nodes are selected via the generic resource (–gres=) and constraints (-C,–constraint=) options:
- k20m (kepler) GPU nodes:
#SBATCH -C k20m #SBATCH --gres=gpu:2
- m60 (maxwell) GPU nodes:
#SBATCH -C m60 #SBATCH --gres=gpu:2
- gtx1080 (pascal) GPU nodes:
#SBATCH -C gtx1080 #SBATCH --gres=gpu:1
- at idle times of private-shared gtx1080 (pascal) GPU nodes:
#SBATCH --partition=p70971_gpu #SBATCH -C gtx1080 #SBATCH --gres=gpu:8
To use a gpu node for computing purposes the quality of service (QoS) gpu_compute is available which provides a maximum runtime of three days:
#SBATCH --qos=gpu_compute
For visualization the QoS gpu_vis has to be used where a gpu node can be occupied for up to twelve hours for interactive visualization:
#SBATCH --qos=gpu_vis
When a job is submitted within the gpu_vis QoS, an X server is started on the gpu node.
Visualization
To make use of a gpu node for visualization you need to perform the following steps.
- set a vnc password, this is needed when connecting to the vnc server, this has to be done only once:
module load TurboVNC/2.0.1 mkdir ${HOME}/.vnc vncpasswd Password: ****** Warning: password truncated to the length of 8. Verify: ****** Would you like to enter a view-only password (y/n)? n - allocate gpu nodes with this script:
sviz -a
- start vnc server:
sviz -r
- follow the instructions on the screen and connect from your local machine with a vncvier:
vncviewer -via <user>@vsc3.vsc.ac.at <node>::<port>
All options for sviz:
sviz -h usage: /opt/sw/x86_64/generic/bin/sviz Parameters: -h print this help -a allocate gpu nodes -r start vnc server on allocated nodes options for allocating: -t set gpu type; default=gtx1080 -n set gpu count; default=1 options for vnc server: -g set geometry; default=1920x1080
Linux/Windows - Tightvnc
On your local (Linux) workstation you can use any vnc client which supports a gateway parameter (usually, there is a -via option), e.g. TightVNC. You will be first asked for your VSC cluster password (and possibly your OTP if it has not been entered within the last 12 hours), and then for your VNC password which you entered in the previous step:
user@localhost:~$ vncviewer -via user@vsc3.vsc.ac.at n25-001::5901 Password: Connected to RFB server, using protocol version 3.8 Enabling TightVNC protocol extensions Performing standard VNC authentication Password: Authentication successful Desktop name "TurboVNC: n25-001:1 (user)" VNC server default format: 32 bits per pixel. Least significant byte first in each pixel. True colour: max red 255 green 255 blue 255, shift red 16 green 8 blue 0 Warning: Cannot convert string "-*-helvetica-bold-r-*-*-16-*-*-*-*-*-*-*" to type FontStruct Using default colormap which is TrueColor. Pixel format: 32 bits per pixel. Least significant byte first in each pixel. True colour: max red 255 green 255 blue 255, shift red 16 green 8 blue 0 Tunneling active: preferring tight encoding
You should now see a desktop like this:

Windows versions of TightVNC are also available.
OS X/Linux/Windows - TuboVNC
Under OS X it is suggested to use the TurboVNC client; but it may be used under Linux or Windows as well. This is how you can setup the client connection to the VNC server:
- Setup the connection:
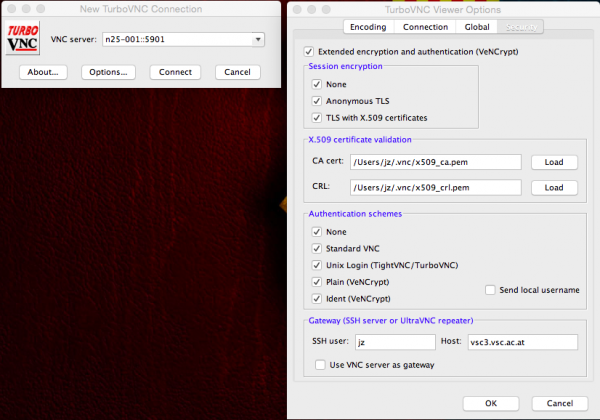
- Enter your cluster password:
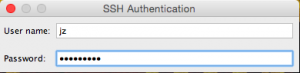
- Enter your OTP:
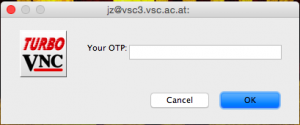
- Enter your VNC password:
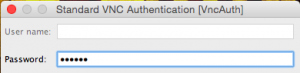




A desktop will be displayed on your screen:

VirtualGL
Load the module
module load VirtualGL/2.5.2
The following variables need to be set:
export VGL_DISPLAY=:0 export DISPLAY=:1
To make use of VirtualGL your application needs to be started with vglrun:
[user@n25-001 ~]$ vglrun <path_to_your_X_application>
GPU computing
CUDA
Cuda toolkits are available in version 5.5, 7.5, 8.0.27 and 8.0.61 (which provide e.g. the nvcc compiler) and are accessible by loading the corresponding cuda module:
module load cuda/5.5
or
module load cuda/7.5
or
module load cuda/8.0.27
or
module load cuda/8.0.61
Batch jobs
To submit batch jobs, a sample job script my_gpu_job_script is:
#!/bin/sh #SBATCH -J gpucmp #SBATCH -N 1 #SBATCH --partition=gpu #SBATCH --qos=gpu_compute #SBATCH --time=00:10:00 #SBATCH --gres=gpu:2 #SBATCH -C k20m ./my_code_which_runs_on_a_gpu
Submit the job:
[user@l31 ~]$ sbatch my_gpu_job_script
Controlling GPU utilization with nvidia-smi
The standard way to check whether an application actually makes use of GPUs and to what extent is by calling
nvidia-smi
or better within a separate terminal
watch nvidia-smi
For further details please see the man page of nvidia-smi
CUDA C References
CUDA Libraries References
Additional Docu
More details found in dir …cuda/8.0.61/doc/pdf upon loading the corresponding cuda module.