
Ansys Workbench and Ansys Fluent (CFD)
General Workflow
To generate your workflow for Ansys most effectively, we recommend utilizing the interactive access, generating the workflow there (noMachine). Additionally, instructions for the RSM Scheduler, are available:TUCOLAB- Ansys
Module
Discover the available versions of Ansys by executing the following command in your terminal:
module avail 2>&1 | grep -i Ansys
and load your preferred Ansys module, e.g.,
module load *your preferred module*
Pre- and postprocessing locally & remote computation on VSC
For utilizing Ansys Workbench and Ansys Fluent, the RSM Scheduler presents an effective option. You can find comprehensive guidance on its usage here:TU COLAB- Ansys RSM
Ansys Fluent
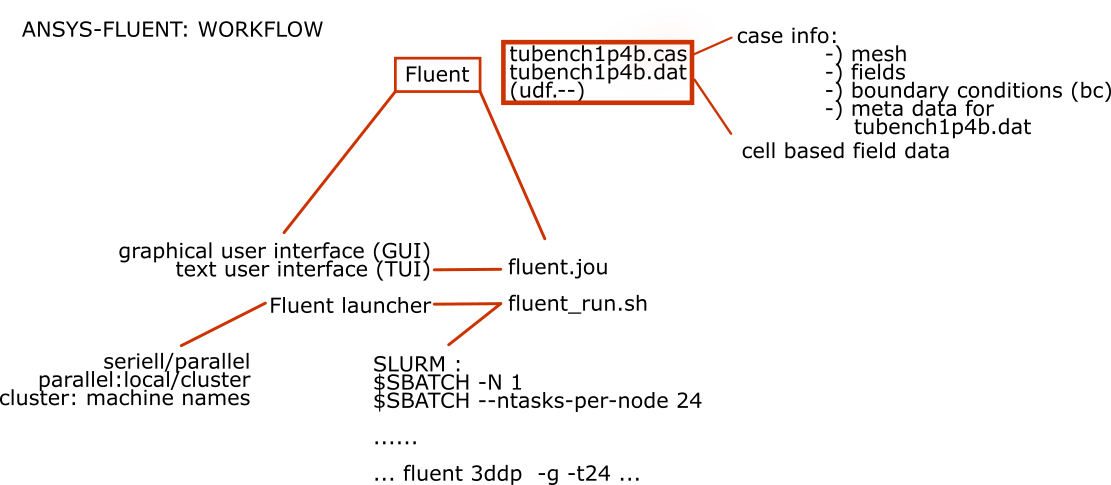
The following provides a comprehensive overview of a typical workflow scenario when utilizing Fluent on your local machine for pre- and post-processing, or through noMachine (we highly recommend the use of noMachine for interactive access), along with instructions on how to submit the Fluent job to the cluster.
For learning and testing how to submit a job to the cluster on one node with multiple cores (24), we provide a test file for Fluent; instructions:
- Start Ansys Fluent and open the .cas file.
- Write a .cas and .dat file out.
- Submit your Slurm submit script with the following command in the terminal:
sbatch fluent_run.sh
- Check the allocated number of processes using the terminal commands: logging into the computing nodes and running htop and top.
- Check the status of your job in the fluent.out file (not the slurm.out file).
- When the job is finished, open/write the .dat file and check the results.
All files needed for this testcase are provided here: fluent_testcase.zip
Input file
You can now create your own input file (Fluent journal file (fluent.jou)). If you choose to do so, please write it using a Linux editor. Be mindful that sometimes converting tools from Windows editor text files to Linux editor text files do not work properly.
This file instructs Ansys Fluent to read, run, and write files.
Alternatively, you may consider adding commands in the Console (TUI) of Ansys or using the Ansys GUI. However, we recommend this approach only for smaller files, primarily for training and testing individual commands. The TUI is primarily intended for experimenting with commands in smaller Ansys Fluent files, with the intention of later writing the necessary commands in the input file (for bigger files).
A basic template for the journal file is provided below:
# ----------------------------------------------------------- # SAMPLE JOURNAL FILE # read case file (*.cas.gz) that had previously been prepared file/read-case "tubench1p4b.cas.gz" solve/init/initialize-flow solve/iterate 500 file/write-data "tubench1p4b.dat.gz" exit yes
Preferably you can set these settings in the GUI, as shown here for the autosave frequency in the subsequent graphic. Please be mindful, that different Ansys versions have different settings!
 Keep in mind to set the appropriate path for your directories for the cluster. Here the files will be saved in the same directory as the journal file is located.
Keep in mind to set the appropriate path for your directories for the cluster. Here the files will be saved in the same directory as the journal file is located.
The autosave/data-frequency setting will save a *.dat file every 10 iterations, the flow field is initialised to zero and then the iteration is started.
Job script
When executing Slurm jobs for Fluent, it's essential to consider specific parameters within the command, including:
- 2d: Indicates a job for 2D Fluent simulations.
- 2ddp: Denotes 2D Fluent jobs in double precision.
- 3d: Specifies a job for 3D Fluent simulations.
- 3ddp: Represents 3D Fluent jobs configured for double precision.
These parameters play a crucial role in defining the type and precision of the Fluent simulations run through Slurm.
Single node script
Below is a script for running Ansys/Fluent called fluent_run.sh for a 3D case with double precision.
#!/bin/sh
#SBATCH -J fluent
#SBATCH -N 1
#SBATCH -o job.%j.out
#SBATCH --ntasks-per-node=24
module purge
module load *your preferred module*
JOURNALFILE=fluent.jou
time fluent 3ddp -g -t 24 < "./$JOURNALFILE" > fluent.out
License server settings
These variables are defined when loading the fluent module file:
setenv ANSYSLI_SERVERS 2325@LICENSE.SERVER setenv ANSYSLMD_LICENSE_FILE 1055@LICENSE.SERVER
Submit job
sbatch fluent_run.sh
Restarting a calculation
To restart a fluent job, you can read in the latest data file:
# read case file (*.cas.gz) that had previously been prepared file/read-case "MyCaseFile.cas.gz" file/read-data "MyCase_-1-00050.dat.gz" # read latest data file and continue calculation solve/init/initialize-flow solve/iterate 500 file/write-data "MyCase.dat.gz" exit yes